

On March 10, 2026, Google launched in public preview Gemini Embedding 2, a model that not only generates text embeddings but unifies text, images, audio, video and PDFs into a single vector space. For those of us building semantic search systems or RAG pipelines, this changes the rules of the game considerably.
In this article I explain from scratch what an embedding is, why it matters, and what makes this new model special.
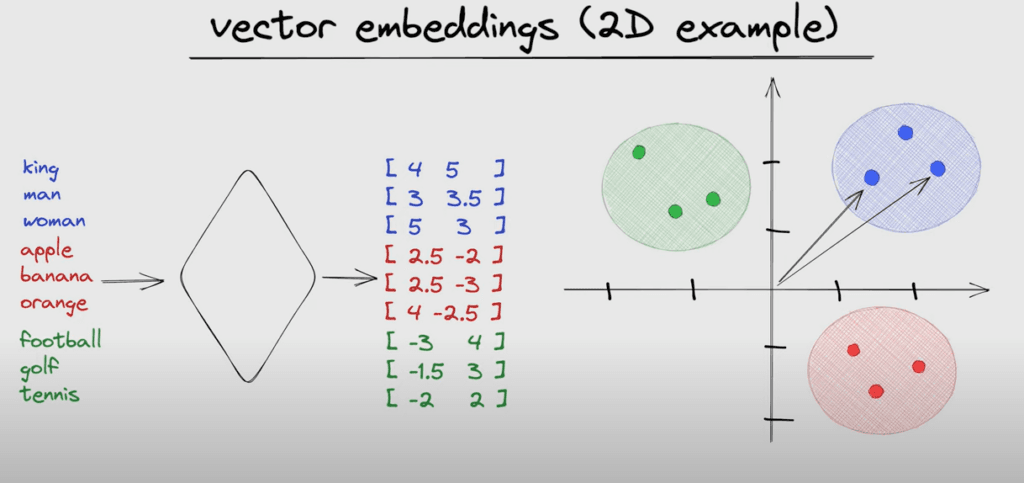
1. What Is an Embedding?
An embedding is a numerical representation of a piece of data (text, image, audio, etc.) in the form of a high-dimensional vector. The core idea is that elements with similar meaning produce vectors that are close together in that space.
Concrete example
If you pass the phrases "dog" and "hound" through an embeddings model, you will get two vectors very close to each other. In contrast, "dog" and "car" will produce distant vectors.
embed("dog") → [0.82, -0.14, 0.33, ...] // close to
embed("hound") → [0.80, -0.12, 0.31, ...] // ✓ similar
embed("car") → [-0.21, 0.67, -0.45, ...] // ✗ distant
This property makes embeddings the foundation of technologies such as semantic search (finding documents by meaning, not exact words), RAG systems (Retrieval-Augmented Generation), and recommendation engines.
Semantic Search
Finds relevant results even when the user does not use the exact words from the document.
RAG Systems
LLMs retrieve relevant context from vector databases before generating responses.
Classification
Group documents, detect duplicates, detect spam, or classify content automatically.
2. What Is Gemini Embedding 2?
Gemini Embedding 2 (gemini-embedding-2-preview) is Google's most recent embeddings model, available on Vertex AI since March 10, 2026. Its key differentiator compared to previous models like text-embedding-004 is that it is multimodal by design: it can generate embeddings from text, images, audio, video and PDFs, mapping all these types into a single shared vector space.
Technical Specifications
Input capabilities
- • Text: up to 8,192 tokens
- • Images: up to 6 images (PNG, JPEG)
- • Video: up to 80–120 seconds (MP4, MPEG)
- • Audio: up to 80 seconds (MP3, WAV)
- • PDF: 1 file, up to 6 pages (with OCR)
Output
- • Dimensions: 3,072 by default
- • Reducible via MRL (Multi-Resolution Learning)
- • Region: us-central1
- • Format: float vector
- • Pricing: Standard PayGo
3. Key Advantages Over Previous Models
Google's previous embedding models (such as text-embedding-004 or multimodalembedding@001) had important limitations: they were unimodal or multimodal but with less context capacity and no task instructions. Gemini Embedding 2 surpasses these on several fronts.
Unified Multimodal Vector Space
The most important advantage. Previously you needed separate models for text and images, plus some fusion mechanism. With Gemini Embedding 2, a text search can return relevant images (and vice versa), because all content types live in the same vector space.
Example use case:
Query: "microservices architecture diagram" (text)
→ Returns architecture diagrams, technical PDFs and relevant conference videos, all in the same search.
Task Instructions: Context-Optimized Embeddings
You can tell the model the type of task for which the embedding will be used. This adjusts the vector representation to optimize accuracy for that specific context.
// Task instruction examples
{
"task_type": "RETRIEVAL_DOCUMENT", // for indexing documents
"task_type": "RETRIEVAL_QUERY", // for search queries
"task_type": "CODE_RETRIEVAL_QUERY", // for code search
"task_type": "SEMANTIC_SIMILARITY", // for similarity comparison
"task_type": "CLASSIFICATION", // for classification
"task_type": "CLUSTERING" // for clustering
}This feature significantly improves retrieval accuracy on benchmarks compared to generic embeddings without a task instruction.
Adjustable Dimensions with MRL
3,072 dimensions by default are a lot — higher semantic precision but greater storage cost and search latency. Thanks to Multi-Resolution Learning (MRL), you can reduce dimensions without retraining the model, adjusting the balance between precision and performance.
Native OCR for PDFs and Audio Extraction from Video
No need to preprocess PDFs with external tools. The model automatically applies OCR to extract text from scanned documents. For videos, it automatically extracts and processes the audio interleaved with visual frames, capturing the semantics of both channels simultaneously.
4. How to Use It: Practical Python Example
The model is accessed through Vertex AI. Here is a basic example of how to generate text and image embeddings in the same vector space:
Text embedding with task instruction
import vertexai
from vertexai.preview.vision_models import MultiModalEmbeddingModel
vertexai.init(project="my-project", location="us-central1")
model = MultiModalEmbeddingModel.from_pretrained("gemini-embedding-2-preview")
# Text embedding with task instruction
text_embeddings = model.get_embeddings(
contextual_text="How do microservices communicate in a distributed system?",
task_type="RETRIEVAL_QUERY",
output_dimensionality=1024 # reduce with MRL
)
print(f"Dimensions: {len(text_embeddings.text_embedding)}")
# Output: Dimensions: 1024Multimodal embedding (text + image in the same space)
from vertexai.preview.vision_models import Image
# Image embedding
image = Image.load_from_file("architecture-diagram.png")
image_embeddings = model.get_embeddings(
image=image,
output_dimensionality=1024
)
# Text embedding (same query)
text_embeddings = model.get_embeddings(
contextual_text="microservices architecture diagram",
task_type="RETRIEVAL_QUERY",
output_dimensionality=1024
)
# Now you can compare text with image directly
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
similarity = cosine_similarity(
text_embeddings.text_embedding,
image_embeddings.image_embedding
)
print(f"Text-image similarity: {similarity:.4f}")
# If high → the image is relevant for the text queryPDF embedding with automatic OCR
from vertexai.preview.vision_models import Video, VideoSegmentConfig
# Embedding a scanned PDF (automatic OCR)
pdf_embeddings = model.get_embeddings(
video=None,
image=None,
contextual_text=None,
pdf="gs://my-bucket/technical-report.pdf", # Google Cloud Storage
output_dimensionality=1024
)
# The model applies OCR internally — no preprocessing needed
print(f"Generated embedding: {len(pdf_embeddings.text_embedding)} dims")5. Most Relevant Use Cases
Multimodal RAG
Build RAG pipelines where retrieved context can be text, document images, slides or training videos — all indexed and searchable with a single model.
Ideal for: enterprise knowledge bases, technical support, product documentation.
Code Search
With CODE_RETRIEVAL_QUERY, you can build semantic code search engines that understand intent, not just keywords.
Ideal for: IDEs with semantic search, AI-assisted code review tools.
Visual E-commerce
Product search by image: the user uploads a photo and the system retrieves visually similar products from the catalog, without needing tags.
Ideal for: marketplaces, fashion catalogs, home decor platforms.
Multimedia Content Analysis
Moderate content, detect duplicates or classify videos and audio at scale, using vectors instead of frame-by-frame processing.
Ideal for: content platforms, media, surveillance systems.
6. Limitations to Keep in Mind
Points to consider before adopting
- Public preview: no production SLA yet. Do not use in critical systems without evaluating stability.
- us-central1 only: if your infrastructure is in another region, you will have additional latency or data compliance restrictions.
- No batch prediction: does not support batch processing. To index millions of documents you will need to orchestrate parallel calls.
- PDFs limited to 6 pages: for long documents you will need to split them into chunks before sending.
- Knowledge cutoff November 2025: like any trained model, it may not capture very recent terminology well.
Want to integrate multimodal embeddings into your product?
I build RAG systems, semantic search and AI pipelines for production. If you have a project where you need to process documents, images or video with intelligent search, let's talk.
Conclusion
Gemini Embedding 2 is not an incremental update — it is a paradigm shift in how we think about embeddings. The ability to unify text, images, audio, video and PDFs in the same vector space opens up use cases that previously required multiple specialized models and complex fusion layers.
For those of us building RAG systems or semantic search, the task instructions and adjustable dimensions with MRL are features that in practice improve both accuracy and operational cost. It is worth evaluating now.
Next steps
- • Create a Google Cloud project and enable Vertex AI
- • Test the model with your own data using the Python example in this guide
- • Compare retrieval accuracy with your current model using an evaluation set
- • Evaluate whether 1,024 dimensions via MRL are sufficient for your use case
- • Monitor the model's evolution — it is in preview and Google tends to improve these models quickly
