

El 10 de marzo de 2026, Google lanzó en preview público Gemini Embedding 2, un modelo que no solo genera embeddings de texto, sino que unifica texto, imágenes, audio, video y PDFs en un único espacio vectorial. Para quienes construimos sistemas de búsqueda semántica o pipelines RAG, esto cambia bastante las reglas del juego.
En este artículo te explico desde cero qué es un embedding, por qué importa y qué hace especial a este nuevo modelo.
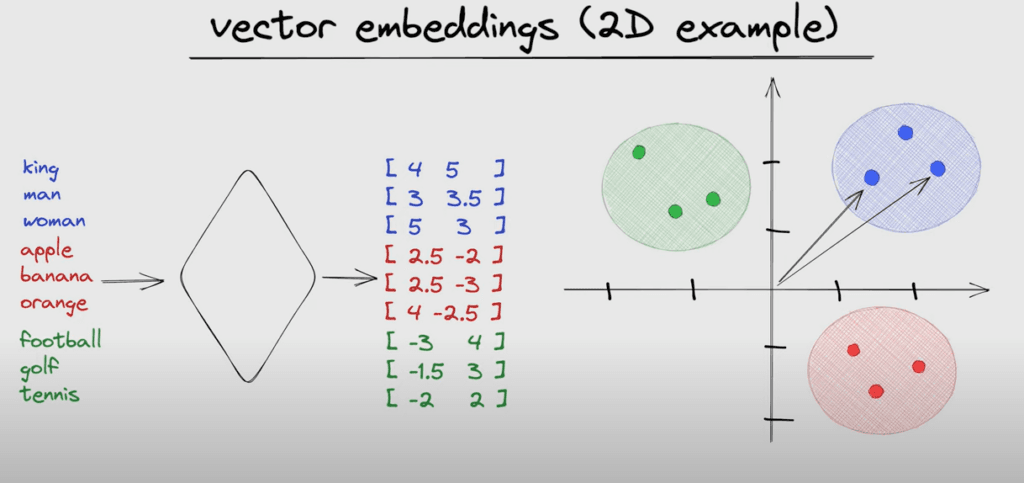
1. ¿Qué es un Embedding?
Un embedding es una representación numérica de un dato (texto, imagen, audio, etc.) en forma de vector de alta dimensión. La idea central es que elementos con significado similar producen vectores cercanos en ese espacio.
Ejemplo concreto
Si pasas las frases "perro" y "can" por un modelo de embeddings, obtendrás dos vectores muy cercanos entre sí. En cambio, "perro" y "automóvil" producirán vectores distantes.
embed("perro") → [0.82, -0.14, 0.33, ...] // cercano a
embed("can") → [0.80, -0.12, 0.31, ...] // ✓ similar
embed("auto") → [-0.21, 0.67, -0.45, ...] // ✗ lejano
Esta propiedad hace que los embeddings sean la base de tecnologías como la búsqueda semántica (encontrar documentos por significado, no por palabras exactas), los sistemas RAG (Retrieval-Augmented Generation) y los motores de recomendación.
Búsqueda Semántica
Encuentra resultados relevantes aunque el usuario no use las palabras exactas del documento.
Sistemas RAG
Los LLMs recuperan contexto relevante desde bases de datos vectoriales antes de generar respuestas.
Clasificación
Agrupar documentos, detectar duplicados, detectar spam o clasificar contenido automáticamente.
2. ¿Qué es Gemini Embedding 2?
Gemini Embedding 2 (gemini-embedding-2-preview) es el modelo de embeddings más reciente de Google, disponible en Vertex AI desde el 10 de marzo de 2026. Su diferenciador clave frente a modelos anteriores como text-embedding-004 es que es multimodal desde su diseño: puede generar embeddings de texto, imágenes, audio, video y PDFs, mapeando todos estos tipos en un único espacio vectorial compartido.
Especificaciones Técnicas
Capacidades de entrada
- • Texto: hasta 8,192 tokens
- • Imágenes: hasta 6 imágenes (PNG, JPEG)
- • Video: hasta 80-120 segundos (MP4, MPEG)
- • Audio: hasta 80 segundos (MP3, WAV)
- • PDF: 1 archivo, hasta 6 páginas (con OCR)
Salida
- • Dimensiones: 3,072 por defecto
- • Reducible via MRL (Multi-Resolution Learning)
- • Región: us-central1
- • Formato: vector de floats
- • Precio: Standard PayGo
3. Ventajas Clave Frente a Modelos Anteriores
Los modelos de embeddings anteriores de Google (como text-embedding-004 o multimodalembedding@001) tenían limitaciones importantes: eran unimodales o multimodales pero con menor capacidad de contexto y sin instrucciones de tarea. Gemini Embedding 2 supera estos puntos en varios frentes.
Espacio Vectorial Unificado Multimodal
La ventaja más importante. Antes necesitabas modelos separados para texto e imágenes y luego algún mecanismo de fusión. Con Gemini Embedding 2, una búsqueda de texto puede retornar imágenes relevantes (y viceversa), porque todos los tipos de contenido viven en el mismo espacio vectorial.
Ejemplo de uso:
Query: "diagrama de arquitectura de microservicios" (texto)
→ Retorna imágenes de diagramas, PDFs técnicos y videos de conferencias relevantes, todo en la misma búsqueda.
Task Instructions: Embeddings Optimizados por Contexto
Puedes indicarle al modelo el tipo de tarea para la que se usará el embedding. Esto ajusta la representación vectorial para optimizar la precisión en ese contexto específico.
// Ejemplos de task instructions
{
"task_type": "RETRIEVAL_DOCUMENT", // para indexar documentos
"task_type": "RETRIEVAL_QUERY", // para queries de búsqueda
"task_type": "CODE_RETRIEVAL_QUERY", // para búsqueda de código
"task_type": "SEMANTIC_SIMILARITY", // para comparar similitud
"task_type": "CLASSIFICATION", // para clasificación
"task_type": "CLUSTERING" // para agrupación
}Esta característica mejora significativamente la precisión en benchmarks de recuperación frente a embeddings genéricos sin instrucción de tarea.
Dimensiones Ajustables con MRL
3,072 dimensiones por defecto son muchas — mayor precisión semántica pero mayor costo de almacenamiento y latencia de búsqueda. Gracias a Multi-Resolution Learning (MRL), puedes reducir las dimensiones sin re-entrenar el modelo, ajustando el balance entre precisión y rendimiento.
OCR Nativo en PDFs y Extracción de Audio en Video
No necesitas preprocesar PDFs con herramientas externas. El modelo aplica OCR automáticamente para extraer texto de documentos escaneados. Para videos, extrae y procesa el audio de forma automática interleándolo con los frames visuales, capturando la semántica de ambos canales simultáneamente.
4. Cómo Usarlo: Ejemplo Práctico con Python
El modelo se accede a través de Vertex AI. Aquí un ejemplo básico de cómo generar embeddings de texto y de imagen en el mismo espacio vectorial:
Embedding de texto con task instruction
import vertexai
from vertexai.preview.vision_models import MultiModalEmbeddingModel
vertexai.init(project="my-project", location="us-central1")
model = MultiModalEmbeddingModel.from_pretrained("gemini-embedding-2-preview")
# Embedding de texto con task instruction
text_embeddings = model.get_embeddings(
contextual_text="How do microservices communicate in a distributed system?",
task_type="RETRIEVAL_QUERY",
output_dimensionality=1024 # reducir con MRL
)
print(f"Dimensiones: {len(text_embeddings.text_embedding)}")
# Output: Dimensiones: 1024Embedding multimodal (texto + imagen en el mismo espacio)
from vertexai.preview.vision_models import Image
# Embedding de imagen
image = Image.load_from_file("architecture-diagram.png")
image_embeddings = model.get_embeddings(
image=image,
output_dimensionality=1024
)
# Embedding de texto (misma query)
text_embeddings = model.get_embeddings(
contextual_text="microservices architecture diagram",
task_type="RETRIEVAL_QUERY",
output_dimensionality=1024
)
# Ahora puedes comparar texto con imagen directamente
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
similarity = cosine_similarity(
text_embeddings.text_embedding,
image_embeddings.image_embedding
)
print(f"Similitud texto-imagen: {similarity:.4f}")
# Si es alta → la imagen es relevante para la query de textoEmbedding de PDF con OCR automático
from vertexai.preview.vision_models import Video, VideoSegmentConfig
# Embedding de un PDF escaneado (OCR automático)
pdf_embeddings = model.get_embeddings(
video=None,
image=None,
contextual_text=None,
pdf="gs://my-bucket/technical-report.pdf", # Google Cloud Storage
output_dimensionality=1024
)
# El modelo hace OCR internamente — no necesitas preprocesar
print(f"Embedding generado: {len(pdf_embeddings.text_embedding)} dims")5. Casos de Uso Más Relevantes
RAG Multimodal
Construir pipelines RAG donde el contexto recuperado puede ser texto, imágenes de documentos, diapositivas o videos de capacitación — todo indexado y buscable con un solo modelo.
Ideal para: bases de conocimiento empresarial, soporte técnico, documentación de producto.
Búsqueda de Código
Con CODE_RETRIEVAL_QUERY, puedes construir buscadores de código semánticos que entiendan intención, no solo keywords.
Ideal para: IDEs con búsqueda semántica, herramientas de code review asistido por IA.
E-commerce Visual
Búsqueda de productos por imagen: el usuario sube una foto y el sistema recupera los productos visualmente similares del catálogo, sin necesidad de etiquetas.
Ideal para: marketplaces, catálogos de moda, plataformas de decoración.
Análisis de Contenido Multimedia
Moderar contenido, detectar duplicados o clasificar videos y audios a escala, usando vectores en lugar de procesamiento frame a frame.
Ideal para: plataformas de contenido, medios, sistemas de vigilancia.
6. Limitaciones a Tener en Cuenta
Puntos a considerar antes de adoptar
- Preview público: aún no tiene SLA de producción. No usar en sistemas críticos sin evaluar estabilidad.
- Solo us-central1: si tu infraestructura está en otra región, tendrás latencia adicional o restricciones de compliance de datos.
- Sin batch prediction: no soporta procesamiento por lotes. Para indexar millones de documentos necesitarás orquestar llamadas paralelas.
- PDFs limitados a 6 páginas: para documentos largos deberás dividirlos en chunks antes de enviarlos.
- Conocimiento hasta noviembre 2025: como cualquier modelo entrenado, puede no capturar bien terminología muy reciente.
¿Querés integrar embeddings multimodales en tu producto?
Construyo sistemas RAG, búsqueda semántica y pipelines de IA para producción. Si tenés un proyecto donde necesitás procesar documentos, imágenes o video con búsqueda inteligente, hablemos.
Conclusión
Gemini Embedding 2 no es una actualización incremental — es un cambio de paradigma en cómo pensamos los embeddings. La capacidad de unificar texto, imágenes, audio, video y PDFs en un mismo espacio vectorial abre casos de uso que antes requerían múltiples modelos especializados y complejas capas de fusión.
Para los que construimos sistemas RAG o búsqueda semántica, las task instructions y las dimensiones ajustables con MRL son features que en la práctica mejoran tanto la precisión como el costo operativo. Vale la pena evaluarlo ya.
Próximos pasos
- • Crear un proyecto en Google Cloud y habilitar Vertex AI
- • Testear el modelo con tus propios datos usando el ejemplo de Python de esta guía
- • Comparar precisión de retrieval con tu modelo actual usando un set de evaluación
- • Evaluar si las 1,024 dimensiones via MRL son suficientes para tu caso de uso
- • Monitorear la evolución del modelo — está en preview y Google suele mejorar estos modelos rápidamente
